
Alibaba Takes Aim at Google & OpenAI: Meet Qwen2.5-Omni, the Open-Source AI That Sees, Hears, and Speaks
The AI arms race just got another major contender. While Google’s Gemini and OpenAI have been dazzling us with their multimodal capabilities—understanding images, video, and audio alongside text—Alibaba’s Qwen team quietly dropped a potential bombshell: Qwen2.5-Omni. This isn't just another large language model; it's pitched as an "omnidirectional" multimodal AI designed from the ground up to perceive the world more like we do. It processes text, images, audio, and video, responding not just with text, but with synthesized speech in real-time.
Perhaps the most disruptive part? Alibaba has open-sourced the 7-billion parameter version, Qwen2.5-Omni-7B, under an Apache 2.0 license. This move potentially puts sophisticated multimodal AI tools directly into the hands of developers and businesses worldwide, free for commercial use. It’s a bold play, challenging the walled gardens of its major competitors.
What's Under the Hood? The "Thinker-Talker" Architecture
Alibaba didn’t just bolt on senses to an existing LLM. They introduced a novel "Thinker-Talker" architecture.
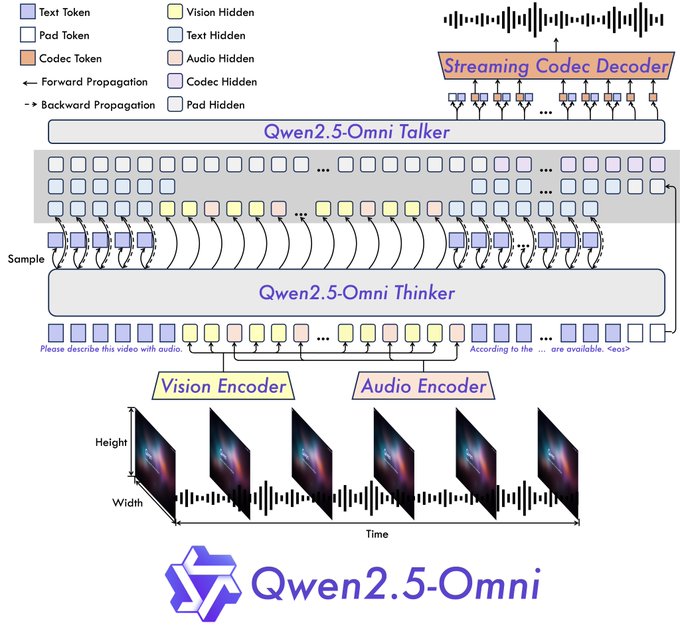
- The Thinker: This component acts like the brain. It takes in the diverse inputs—text, visuals, sounds—and processes them to understand the context and generate high-level semantic representations, along with the core text response. It uses dedicated encoders for audio and vision to extract relevant features.
- The Talker: Functioning like the mouth and vocal cords, the Talker receives the semantic information and text from the Thinker in real-time. It then synthesizes this into discrete audio tokens, generating a stream of natural-sounding speech alongside the written text.
This end-to-end design is crucial for enabling real-time, interactive experiences. The architecture supports chunked inputs and immediate outputs, aiming for conversations that feel more like a video call than a turn-based chat.
Furthermore, Qwen2.5-Omni incorporates a new position embedding technique called TMRoPE (Time-aligned Multimodal RoPE). This specifically addresses a tricky problem: accurately synchronizing video frames with their corresponding audio segments along a shared timeline. Getting this right is vital for understanding actions and speech within video content correctly.
Performance Claims vs. Real-World Tests: Impressive Senses, Questionable Smarts?
Alibaba claims Qwen2.5-Omni achieves state-of-the-art results on OmniBench, a benchmark designed for integrated multimodal tasks. They also report that it outperforms similarly sized models, including closed-source competitors like Google's Gemini 1.5 Pro on certain tasks, and even specialized single-modal models from their own lineup (like Qwen2.5-VL-7B for vision and Qwen2-Audio).
The official demos and initial user tests paint a fascinating, albeit mixed, picture:
- The Upside – Multimodal Prowess:
- Vision: It accurately identified "suspicious behavior" in a simulated security feed image, providing a correct classification and reasoning.
- Video: Given a dance video, it provided a detailed description of the dancer's attire, movements, and the setting.
- Audio: It correctly summarized the steps for making Red Braised Pork from an uploaded audio recipe.
- Interaction: The simultaneous text and natural-sounding voice output (handling mixed English/Chinese well) is fast and fluid, creating a genuinely conversational feel. Demos showcase video calls where the AI describes surroundings, acts as a voice-guided recipe assistant, critiques song drafts, analyzes sketches, and even tutors math problems step-by-step from a photo.
- The Downside – Reasoning Glitches & Practical Hurdles:
- Basic Logic Fails: Despite its advanced sensory processing, the 7B demo model stumbled on simple reasoning tasks. Asked "Which is bigger, 6.9 or 6.11?", it incorrectly stated 6.9 is smaller. Asked how many 'r's are in "strawberry", it answered two (there are three). This suggests a potential gap between perceptual ability and cognitive reasoning, at least in this accessible version.
- Resource Intensity: Some users attempting to run the model locally reported significant VRAM requirements, with one instance citing an Out-of-Memory error on a 100GB VRAM setup for a 21-second video. Others noted errors with larger images and slow generation times (minutes per response), hinting that efficient deployment might require optimization or specific hardware configurations.
- Language & Customization: While English and Chinese voice output is strong, users noted limitations with other languages like Spanish and French. The voice output currently mirrors the text; more customization options would be beneficial for specific applications. Accessibility for non-expert users was also flagged as needing improvement.
The Open-Source Gambit: Democratizing Multimodal AI?
Alibaba's decision to open-source Qwen2.5-Omni-7B under the commercially permissive Apache 2.0 license is perhaps the most strategically significant aspect of this release.
- Lowering Barriers: It allows startups, researchers, and even established companies to experiment with and deploy advanced multimodal AI without exorbitant API costs or licensing fees associated with closed models. This could spur innovation in areas like:
- Accessibility tools: AI that can describe the world for the visually impaired.
- Education: Interactive tutors that can see a student's work and hear their questions.
- Creative Assistance: Tools that critique visual art, music, or writing based on multiple inputs.
- Smart Devices: Enabling more natural interaction with wearables (like the smart glasses concept mentioned by users) or home assistants.
- Competitive Pressure: This move directly challenges the business models of OpenAI and Google, potentially forcing them to reconsider their pricing or offer more accessible versions of their own cutting-edge models. The user comment dubbing this "true OpenAI" reflects a segment of the developer community hungry for powerful, open tools.
- Ecosystem Building: For Alibaba, this could be a play to build a developer ecosystem around its Qwen models, fostering broader adoption and potentially driving usage of its cloud platform where the model is also hosted.
The Takeaway: A Powerful Step, But the Journey Continues
Qwen2.5-Omni is undeniably a significant advancement in multimodal AI, particularly impressive for its seamless integration of diverse inputs and real-time text-and-speech output within a novel architecture. The open-sourcing of the 7B model is a major move that could significantly impact the AI landscape, empowering developers and businesses worldwide.
However, the initial tests highlight a crucial reality: advanced sensory perception doesn't automatically translate to flawless reasoning or effortless deployment. The observed logical errors and reported resource demands show there are still hurdles to overcome.
For businesses and investors, Qwen2.5-Omni represents both an opportunity and a point of observation. The opportunity lies in leveraging this powerful, accessible tool for innovation. The observation point is watching how the model matures, how the community addresses its limitations, and how competitors respond to this open-source challenge. Alibaba has dealt a strong card; the next moves in the high-stakes game of AI are eagerly awaited.
Resources:
- Demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
- Qwen Chat Experience: https://chat.qwen.ai/
- GitHub: https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Face Model: https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- Technical Report: https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
- Blog Post: https://qwenlm.github.io/blog/qwen2.5-omni/