
Google's Gemma 3 QAT Models Democratize Advanced AI for Consumer Hardware
Google has released quantized versions of its powerful Gemma 3 27B QAT model language model, enabling state-of-the-art AI to run on consumer-grade hardware. The new Quantization-Aware Training variants dramatically reduce memory requirements while maintaining performance comparable to their full-precision counterparts, marking a turning point in bringing advanced AI capabilities to personal devices.

Bringing Supercomputer Power to Consumer GPUs
In a small apartment in Brooklyn, software developer Maya Chen runs complex AI image generation and text analysis that would typically require expensive cloud services or specialized hardware. Her secret? A two-year-old NVIDIA RTX 3090 graphics card running Google's newly released Gemma 3 27B QAT model.
"It's revolutionary," Chen explains while demonstrating the system. "I'm running what amounts to supercomputer-level AI on hardware I already owned. Before this release, it simply wasn't possible."
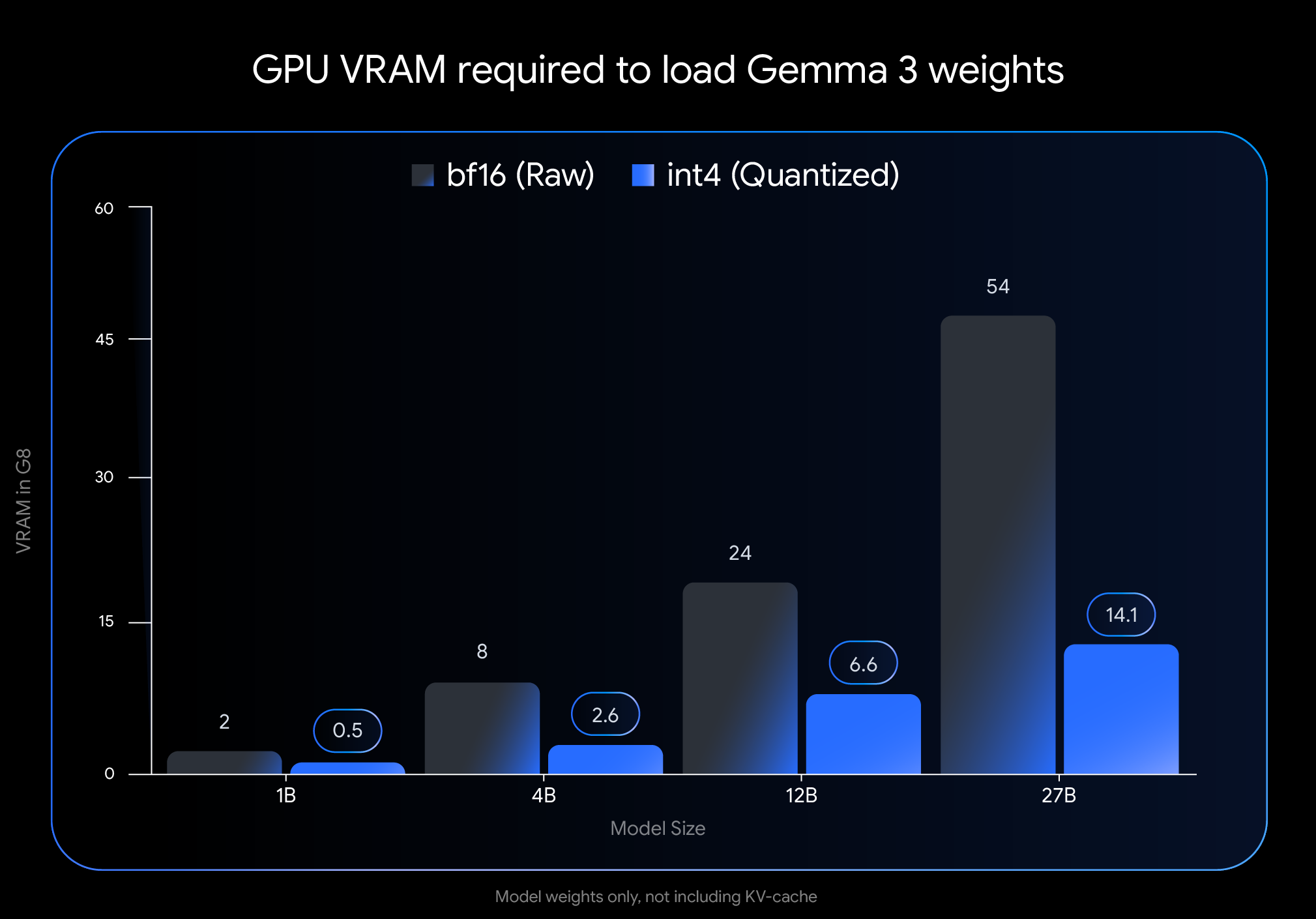
Chen's experience reflects the promise of Google's April 18 announcement: democratizing access to cutting-edge AI by making it run efficiently on widely available consumer hardware. Last month's launch of Gemma 3 established it as a leading open model, but its high memory requirements limited deployment to expensive, specialized hardware. The new QAT variants change this dynamic entirely.
Technical Breakthrough in Model Compression
The quantized models represent a technical breakthrough in AI model compression. Traditional approaches to reducing model size often resulted in significant performance degradation, but Google's implementation of Quantization-Aware Training introduces a novel approach.
Unlike conventional post-training quantization methods, QAT incorporates the compression process during the training phase itself. By simulating low-precision operations during training, the models adapt to function optimally even when ultimately deployed with reduced numerical precision.
"What makes this approach particularly effective is the training methodology," notes a machine learning researcher who has analyzed the models. "By applying QAT on approximately 5,000 steps and using probabilities from non-quantized checkpoints as targets, they've reduced the perplexity drop by 54% compared to standard quantization techniques."
The impact on memory requirements is dramatic. The Gemma 3 27B model's VRAM footprint shrinks from 54GB to just 14.1GB – a reduction of nearly 74%. Similarly, the 12B variant drops from 24GB to 6.6GB, the 4B from 8GB to 2.6GB, and the 1B from 2GB to a mere 0.5GB.
These reductions make previously inaccessible models viable on consumer hardware. The flagship 27B model now runs comfortably on desktop GPUs like the NVIDIA RTX 3090, while the 12B variant can operate efficiently on laptop GPUs such as the NVIDIA RTX 4060.
Real-World Performance Validates Approach
What separates Google's implementation from previous attempts at model quantization is the minimal impact on performance. Independent benchmarks suggest the QAT models maintain accuracy within 1% of their full-precision counterparts.
In the Chatbot Arena Elo rankings, a widely respected measure of AI model performance based on human preferences, Gemma 3 models score impressively high. The 27B variant achieves an Elo score of 1338, placing it among the top open models despite requiring significantly less computing power than competitors.
Community feedback corroborates these official metrics. Users across developer forums report that the QAT models "feel smarter" than other quantized variants. In direct comparisons using the challenging GPQA diamond metric, the Gemma 3 27B QAT outperformed other quantized models while using less memory.
"We've seen near-instantaneous response times in real-time applications," says a developer who integrated the model into a mobile application. "This makes Gemma 3 practical for edge deployments where latency and resource constraints are critical factors."
Multimodal Capabilities Expand Use Cases
Beyond raw performance, Gemma 3 incorporates architectural innovations that expand its capabilities beyond text processing. Integration of a vision encoder enables the models to process images alongside text, though some experts note limitations in the depth of visual understanding compared to larger specialized systems.
Another significant advancement is support for extended context windows – up to 128,000 tokens for most variants and 32,000 for the 1B model. This allows the AI to process much longer documents and conversations than most consumer-accessible models.
"The implementation of an interleaved local/global attention mechanism drastically reduces the memory footprint required for long-context inference," explains a machine learning engineer familiar with the architecture. "This makes it feasible to process extensive documents on consumer GPUs without sacrificing comprehension."
Ecosystem Support Facilitates Adoption
Google has prioritized ease of integration, releasing the models in formats compatible with popular developer tools. Official int4 and Q4_0 unquantized QAT models are available on Hugging Face and Kaggle, with native support from tools including Ollama, LM Studio, MLX for Apple Silicon, Gemma.cpp, and llama.cpp.
This ecosystem support has accelerated adoption among independent developers and researchers. Discussion forums are filled with reports of successful deployments across diverse hardware configurations and use cases.
"The broad tool support and easy setup process have been crucial," says a developer who integrated the model into an educational application. "We were able to deploy locally within hours, eliminating cloud costs while maintaining response quality."
Limitations and Future Directions
Despite the advancements, experts identify several areas where Gemma 3 models still face limitations. While they can process long contexts, some users note that the ability to reason deeply across very extensive inputs remains challenging, particularly for complex analytical tasks.
The vision component, while efficient, is not as sophisticated as in some larger, jointly trained multimodal models. This may affect performance in tasks requiring nuanced visual understanding.
Additionally, some machine learning researchers point out that much of Gemma 3's performance comes from sophisticated knowledge distillation from more powerful teacher models, likely from Google's proprietary Gemini family. This reliance, along with some opacity in the post-training methodology, limits full reproducibility by the broader AI research community.
Democratizing AI Development
The release represents a significant step in making advanced AI capabilities accessible to a wider range of developers, researchers, and enthusiasts. By enabling local deployment on common hardware, Gemma 3 QAT models reduce barriers to entry in terms of both cost and technical requirements.
"This is about more than just technical capabilities," reflects Chen, the Brooklyn developer. "It's about who gets to innovate with these technologies. When powerful AI runs locally on consumer hardware, it opens doors for individuals and small teams who couldn't afford specialized infrastructure."
As AI increasingly influences various aspects of technology development, the ability to run sophisticated models locally may prove transformative for innovation beyond the major technology companies. Google's approach with Gemma 3 QAT suggests a future where state-of-the-art AI becomes a democratized tool rather than a centralized resource.
Whether this vision fully materializes depends on how the technology evolves and how the broader developer community embraces these capabilities. For now, however, the gap between cutting-edge AI research and practical deployment has narrowed significantly – a development with potentially far-reaching implications for the future of AI accessibility.